Posted inEntertainment
Taylor Swift is Now a BILLIONAIRE!
In case the entire world wasn’t already aware, Taylor Swift is a very successful musician. Heck, she seems to be a very successful human being in general when you stop…






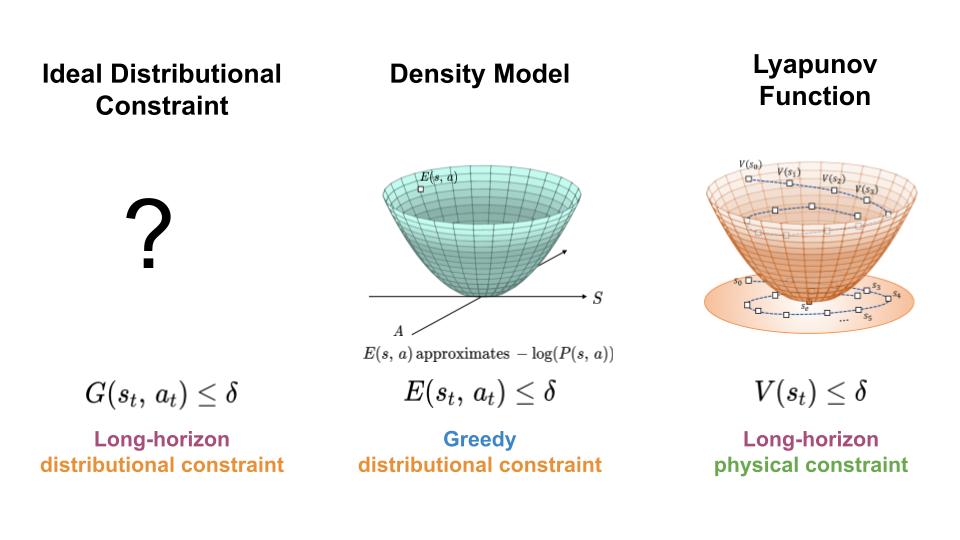
To regulate the distribution shift experience by learning-based controllers, we seek a mechanism for constraining the agent to regions of high data density throughout its trajectory (left). Here, we present an approach which achieves this goal by combining features of density models (middle) and Lyapunov functions (right).
In order to make use of machine learning and reinforcement learning in controlling real world systems, we must design algorithms which not only achieve good performance, but also interact with the system in a safe and reliable manner. Most prior work on safety-critical control focuses on maintaining the safety of the physical system, e.g. avoiding falling over for legged robots, or colliding into obstacles for autonomous vehicles. However, for learning-based controllers, there is another source of safety concern: because machine learning models are only optimized to output correct predictions on the training data, they are prone to outputting erroneous predictions when evaluated on out-of-distribution inputs. Thus, if an agent visits a state or takes an action that is very different from those in the training data, a learning-enabled controller may “exploit” the inaccuracies in its learned component and output actions that are suboptimal or even dangerous.


