Posted inArtificial Intelligence
Interactive Fleet Learning – The Berkeley Artificial Intelligence Research Blog

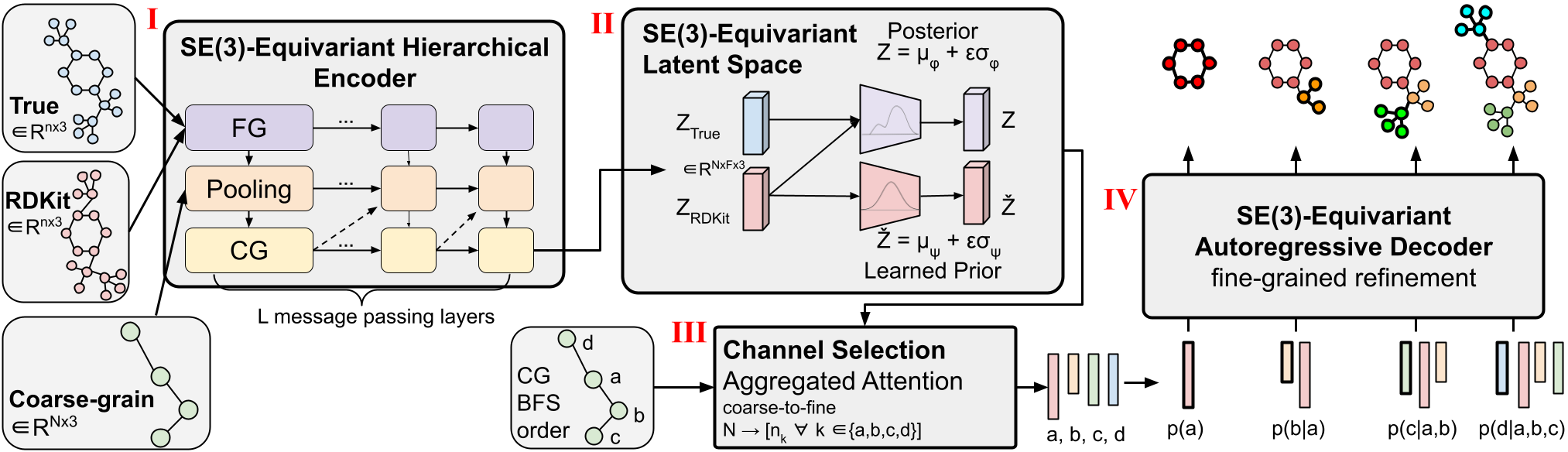
Figure 1: “Interactive Fleet Learning” (IFL) refers to robot fleets in industry and academia that fall back on human teleoperators when necessary and continually learn from them over time.
In the last few years we have seen an exciting development in robotics and artificial intelligence: large fleets of robots have left the lab and entered the real world. Waymo, for example, has over 700 self-driving cars operating in Phoenix and San Francisco and is currently expanding to Los Angeles. Other industrial deployments of robot fleets include applications like e-commerce order fulfillment at Amazon and Ambi Robotics as well as food delivery at Nuro and Kiwibot.