
Function Calling at the Edge – The Berkeley Artificial Intelligence Research Blog

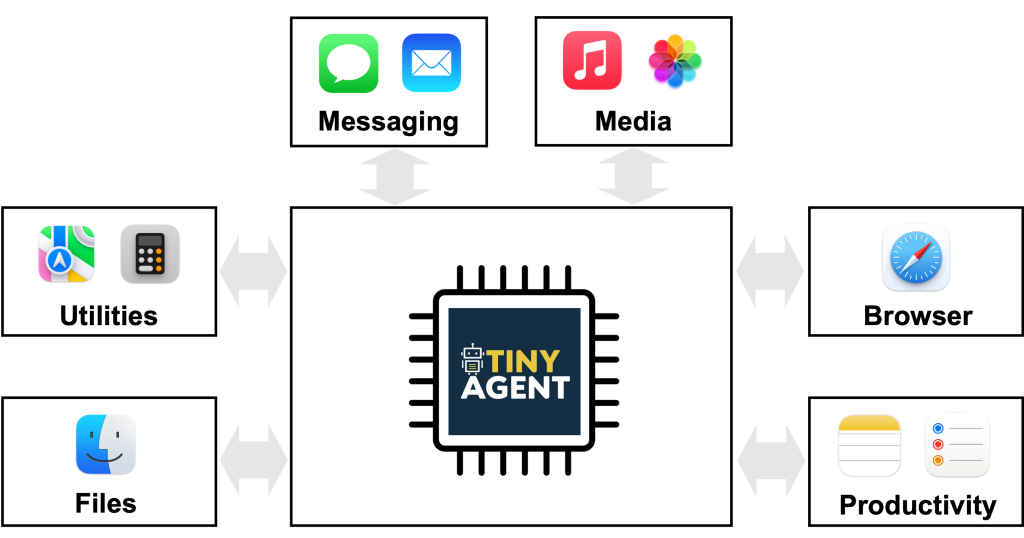
The ability of LLMs to execute commands through plain language (e.g. English) has enabled agentic systems that can complete a user query by orchestrating the right set of tools (e.g. ToolFormer, Gorilla). This, along with the recent multi-modal efforts such as the GPT-4o or Gemini-1.5 model, has expanded the realm of possibilities with AI agents. While this is quite exciting, the large model size and computational requirements of these models often requires their inference to be performed on the cloud. This can create several challenges for their widespread adoption. First and foremost, uploading data such as video, audio, or text documents to a third party vendor on the cloud, can result in privacy issues. Second, this requires cloud/Wi-Fi connectivity which is not always possible. For instance, a robot deployed in the real world may not always have a stable connection. Besides that, latency could also be an issue as uploading large amounts of data to the cloud and waiting for the response could slow down response time, resulting in unacceptable time-to-solution. These challenges could be solved if we deploy the LLM models locally at the edge.