
Rethinking the Role of PPO in RLHF – The Berkeley Artificial Intelligence Research Blog
TL;DR: In RLHF, there’s tension between the reward learning phase, which uses human preference in the form of comparisons, and the RL fine-tuning phase, which optimizes a single, non-comparative reward. What if we performed RL in a comparative way?
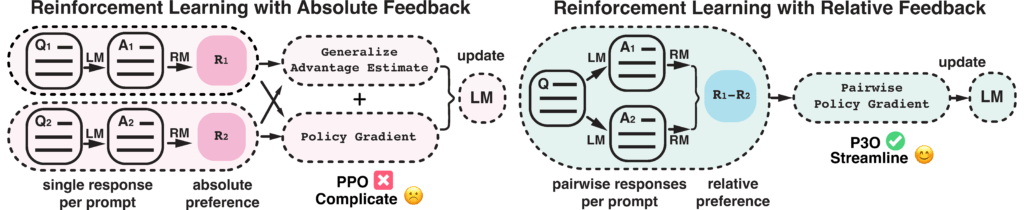
Figure 1:
This diagram illustrates the difference between reinforcement learning from absolute feedback and relative feedback. By incorporating a new component – pairwise policy gradient, we can unify the reward modeling stage and RL stage, enabling direct updates based on pairwise responses.
Large Language Models (LLMs) have powered increasingly capable virtual assistants, such as GPT-4, Claude-2, Bard and Bing Chat. These systems can respond to complex user queries, write code, and even produce poetry. The technique underlying these amazing virtual assistants is Reinforcement Learning with Human Feedback (RLHF). RLHF aims to align the model with human values and eliminate unintended behaviors, which can often arise due to the model being exposed to a large quantity of low-quality data during its pretraining phase.
Proximal Policy Optimization (PPO), the dominant RL optimizer in this process, has been reported to exhibit instability and implementation complications. More importantly, there’s a persistent discrepancy in the RLHF process: despite the reward model being trained using comparisons between various responses, the RL fine-tuning stage works on individual responses without making any comparisons. This inconsistency can exacerbate issues, especially in the challenging language generation domain.
Given this backdrop, an intriguing question arises: Is it possible to design an RL algorithm that learns in a comparative manner? To explore this, we introduce Pairwise Proximal Policy Optimization (P3O), a method that harmonizes the training processes in both the reward learning stage and RL fine-tuning stage of RLHF, providing a satisfactory solution to this issue.