
Detecting Text Ghostwritten by Large Language Models – The Berkeley Artificial Intelligence Research Blog

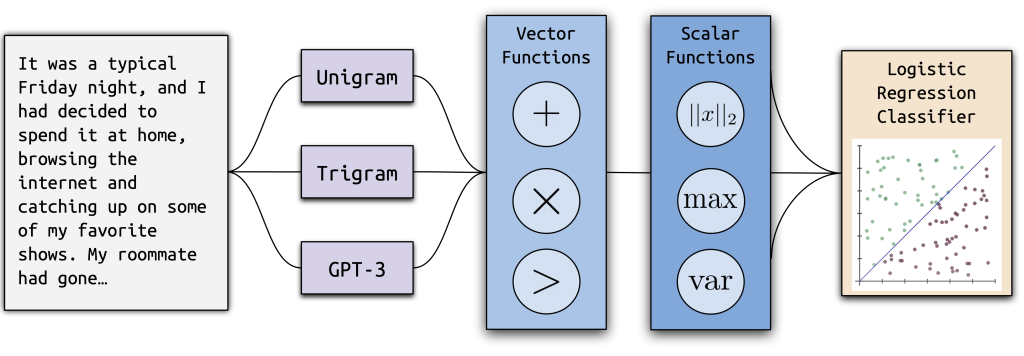
The structure of Ghostbuster, our new state-of-the-art method for detecting AI-generated text.
Large language models like ChatGPT write impressively well—so well, in fact, that they’ve become a problem. Students have begun using these models to ghostwrite assignments, leading some schools to ban ChatGPT. In addition, these models are also prone to producing text with factual errors, so wary readers may want to know if generative AI tools have been used to ghostwrite news articles or other sources before trusting them.
What can teachers and consumers do? Existing tools to detect AI-generated text sometimes do poorly on data that differs from what they were trained on. In addition, if these models falsely classify real human writing as AI-generated, they can jeopardize students whose genuine work is called into question.
Our recent paper introduces Ghostbuster, a state-of-the-art method for detecting AI-generated text. Ghostbuster works by finding the probability of generating each token in a document under several weaker language models, then combining functions based on these probabilities as input to a final classifier. Ghostbuster doesn’t need to know what model was used to generate a document, nor the probability of generating the document under that specific model. This property makes Ghostbuster particularly useful for detecting text potentially generated by an unknown model or a black-box model, such as the popular commercial models ChatGPT and Claude, for which probabilities aren’t available. We’re particularly interested in ensuring that Ghostbuster generalizes well, so we evaluated across a range of ways that text could be generated, including different domains (using newly collected datasets of essays, news, and stories), language models, or prompts.