
Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models – The Berkeley Artificial Intelligence Research Blog
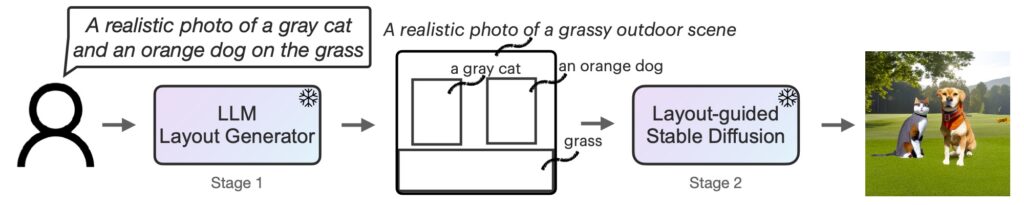
TL;DR: Text Prompt -> LLM -> Intermediate Representation (such as an image layout) -> Stable Diffusion -> Image.
Recent advancements in text-to-image generation with diffusion models have yielded remarkable results synthesizing highly realistic and diverse images. However, despite their impressive capabilities, diffusion models, such as Stable Diffusion, often struggle to accurately follow the prompts when spatial or common sense reasoning is required.
The following figure lists four scenarios in which Stable Diffusion falls short in generating images that accurately correspond to the given prompts, namely negation, numeracy, and attribute assignment, spatial relationships. In contrast, our method, LLM-grounded Diffusion (LMD), delivers much better prompt understanding in text-to-image generation in those scenarios.

Figure 1: LLM-grounded Diffusion enhances the prompt understanding ability of text-to-image diffusion models.